Welcome back to The Code Neuron! In our last blog, we mastered advanced query techniques like CTEs and Window Functions. Now that we can write powerful queries, it’s time to ensure they run as fast as possible. The key to high-performance database operations is indexing. Think of an index like the index at the back of a textbook. Instead of reading the entire book to find a specific topic, you can go to the index, find the page number for that topic, and go directly to the right page. This is exactly what an index does for a database, it allows the SQL Server to quickly find data without scanning the entire table.
Without an index, the SQL Server has to perform a full table scan, which means it reads every single row in the table to find the data you’re looking for. For a small table, this isn’t a problem. But for a table with millions of rows, it can be incredibly slow.
What is an Index?
An index is a disk-based structure that contains a sorted copy of the data from one or more columns of a table. It’s designed to speed up the retrieval of rows by providing a fast access path to the data.
To understand the two main types of indexes, Clustered and Non-Clustered, let’s set up a new database and a simple Products table.
Setting Up Our Sample Database
-- Create a new database for our examples
CREATE DATABASE IndexingExamples;
GO
USE IndexingExamples;
GO
-- Create the Products table
CREATE TABLE Products (
ProductID INT NOT NULL,
ProductName VARCHAR(100) NOT NULL,
Category VARCHAR(50) NOT NULL,
UnitPrice DECIMAL(10, 2) NOT NULL,
PRIMARY KEY (ProductID) -- ProductID is the unique identifier
);
GO
-- Insert some sample data
INSERT INTO Products (ProductID, ProductName, Category, UnitPrice)
VALUES
(1, 'Laptop Pro', 'Electronics', 1200.00),
(2, 'Gaming Mouse', 'Electronics', 75.50),
(3, 'Office Chair', 'Furniture', 250.00),
(4, 'Desk Lamp', 'Furniture', 45.99),
(5, 'Espresso Machine', 'Appliances', 350.00),
(6, 'Smart TV 55"', 'Electronics', 800.00);
GOClustered Index
A Clustered Index physically sorts the rows in a table based on the indexed column’s values. Because the data rows can only be physically stored in one order, a table can have only one clustered index. This index is often created on the primary key of a table, as primary keys are unique and frequently used in queries to retrieve single rows.
Analogy: A phone book is a perfect example of a clustered index. The entire phone book is sorted alphabetically by name. When you look up a name, you don’t have to read every entry; you go to the section where that name should be. The data (phone numbers, addresses) is stored in the same physical order as the index itself.
How It Makes Searching Easy
Imagine a query to find the product with ProductID = 4.
- Without a clustered index: The database has to start at the first row (
ProductID = 1) and check each row sequentially until it finds the row withProductID = 4. This is slow, especially with millions of rows. - With a clustered index: The data is physically sorted by
ProductID. The database uses a B-tree structure to quickly navigate to the data block containingProductIDvalues around 4 and finds the row instantly. It’s like opening a phone book to the ‘D’ section immediately, rather than flipping through from the ‘A’s.
Creating a Clustered Index
When you define a PRIMARY KEY in MSSQL, a clustered index is created by default if one doesn’t already exist.
-- This creates a clustered index on the ProductID column.
-- It is automatically created when you define a PRIMARY KEY constraint.
CREATE CLUSTERED INDEX IX_Products_ProductID
ON Products (ProductID);
GOKey Characteristics:
- A table can have only one clustered index.
- The leaf nodes of a clustered index contain the actual data rows of the table.
- Excellent for range queries and sorting because the data is already in order.
Non-Clustered Index
A Non-Clustered Index is a separate data structure from the table itself. It contains the indexed columns and a pointer (a row locator) to the actual data row in the table. A single table can have multiple non-clustered indexes.
Analogy: A non-clustered index is like the index at the back of a textbook. The index entry tells you that “Relational Databases” is on page 150. The index itself is sorted alphabetically, but the content of the book is not. You find the topic in the index and then use the page number to jump directly to the data.
How It Makes Searching Easy
Let’s say we frequently search for products by their Category. Without an index on Category, the database performs a full table scan.
- Without a non-clustered index: To find all ‘Electronics’, the database reads every row, one by one, checking if
Categoryequals ‘Electronics’. - With a non-clustered index: We create a non-clustered index on
Category. This index is a separate, sorted list of categories and a pointer to the full row for each product. When you search for ‘Electronics’, the database goes to this index, finds all the ‘Electronics’ entries immediately, gets the pointers, and then fetches only those specific rows from the main table. This avoids reading all the other rows, such as those for ‘Furniture’ or ‘Appliances’.
Creating a Non-Clustered Index
Non-clustered indexes are ideal for columns that are frequently used in WHERE clauses but are not the primary key.
-- This creates a non-clustered index on the Category column.
CREATE NONCLUSTERED INDEX IX_Products_Category
ON Products (Category);
GO
-- This query is now much faster because SQL Server can use the index.
SELECT ProductName, UnitPrice
FROM Products
WHERE Category = 'Electronics';The INCLUDE Clause
A covering index is a non-clustered index that includes all the columns needed to satisfy a query. This means SQL Server doesn’t need to perform an extra step to go back to the base table to get the full data. It can get everything it needs from the index itself. This is a powerful performance optimization.
Let’s create a non-clustered index on Category and INCLUDE the ProductName and UnitPrice columns.
CREATE NONCLUSTERED INDEX IX_Products_Category_Covering
ON Products (Category)
INCLUDE (ProductName, UnitPrice);
GONow, a query like this can be executed by reading only the index:
SELECT
ProductName,
UnitPrice
FROM
Products
WHERE
Category = 'Electronics';SQL Server sees that all the requested columns (ProductName, UnitPrice) are available right in the index, along with the filter column (Category). It doesn’t need to touch the main table at all, making the query incredibly fast.
Key Characteristics:
- A table can have multiple non-clustered indexes.
- The leaf nodes contain the key values and row locators to the actual data.
- Can be a “covering index” to avoid looking up data in the base table.
Deciphering Query Execution Plans: The Proof is in the Plan
So, you’ve created your indexes. But how do you know if SQL Server is actually using them? This is where a Query Execution Plan comes in. A query plan is essentially the roadmap that SQL Server uses to execute your query. By looking at the plan, you can see if it’s performing a slow, full table scan or using your shiny new index.
To view an execution plan in SQL Server Management Studio (SSMS), you can simply click the “Display Estimated Execution Plan” button (or press Ctrl + L) before running your query, or “Include Actual Execution Plan” (or press Ctrl + M) to see what happened after the query ran.
Reading the Plan: What to Look For
Let’s examine a simple query to see the difference an index makes.
Scenario 1: No Index on Category
When you run a query filtering on Category without an index, the execution plan will likely show a “Clustered Index Scan” or “Table Scan”. This means the database had to read every single row in the table to find the matching data. It’s a slow and inefficient process.
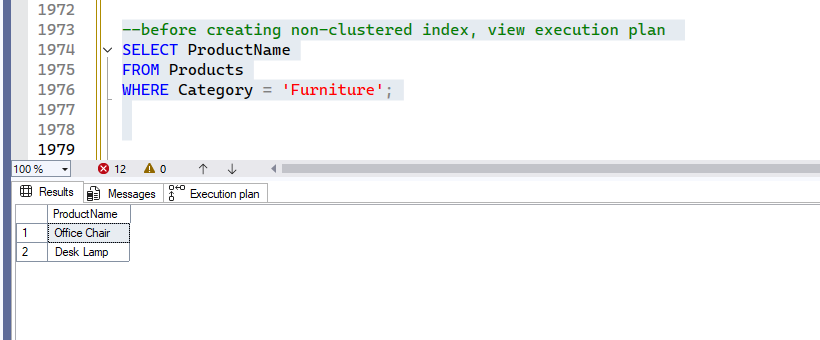
SELECT ProductName
FROM Products
WHERE Category = 'Furniture';Output: Result and Execution Plan.
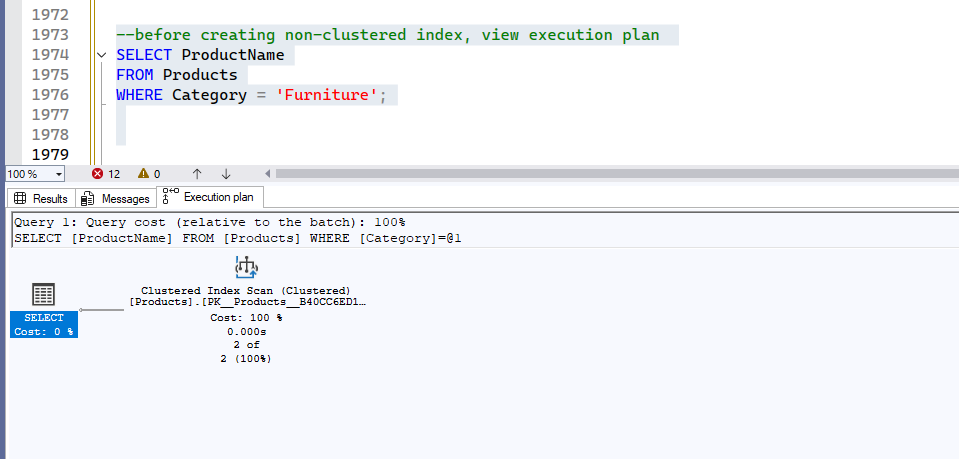
This is what’s happening:
- Clustered Index Scan: The database is forced to read every single row in the entire table, from beginning to end, to find the products that match the
Category = 'Furniture'. It can’t use the primary key index (ProductID) for this search because the query is filtering on a different column (Category).
- Cost: 100%: The plan explicitly states this operation accounts for 100% of the query cost, meaning it is the most resource-intensive and slowest part of the query’s execution.
- Result: This is exactly the inefficient behavior that a full table scan represents, as described in the blog post’s first scenario. The database is doing a lot of unnecessary work to find a few specific rows. This is why adding a non-clustered index on the
Categorycolumn is crucial for improving performance.
Scenario 2: With an Index on Category
After you create the non-clustered index IX_Products_Category, the execution plan for the same query will change. The plan will now show a “Non-Clustered Index Seek”. A “seek” is a highly efficient operation where the database goes directly to the required data, much like a book index guiding you to a specific page.
-- Query will now use our new index
SELECT ProductName
FROM Products
WHERE Category = 'Furniture';The difference between a scan and a seek is the proof you need. A seek indicates that the index was used effectively, resulting in a fast query. A scan, on the other hand, means the database had to do a lot of unnecessary work.
Important Note: You might notice that for our tiny Products table, the execution plan still shows a Clustered Index Scan even after you create the non-clustered index. This is a crucial learning point. For very small tables, the SQL Server query optimizer correctly determines that it is more efficient to simply read all the data in the table rather than go through the extra step of using a separate index. The performance benefits of an index are only truly realized on large datasets where the cost of a full scan is significantly higher than the cost of an index seek.
When to Use and When to Be Careful
When to use an index:
- On columns used in
WHERE,JOIN,ORDER BY, orGROUP BYclauses. - On columns that have a high number of unique values.
When to be careful:
- Every index requires storage space.
- Indexes can slow down
INSERT,UPDATE, andDELETEoperations because the database must also update the index structure every time data changes. - Avoid creating indexes on columns with very few unique values (e.g., a column with only ‘Yes’ or ‘No’).
Conclusion
Understanding and correctly applying indexing is one of the most effective ways to optimize your database and improve query performance. By using clustered indexes for primary keys and non-clustered indexes on frequently queried columns, you can drastically reduce query execution time. The ability to read and interpret query execution plans is the final step, giving you a clear view into how your database is performing and allowing you to make informed decisions about your indexing strategy. Choose your indexes wisely, as there is a trade-off between read performance and write performance.
Leave a Reply
You must be logged in to post a comment.